Unlocking the Potential of Apache Kafka: A Comprehensive Overview
Jump To Key Section
- What is Apache Kafka?
- Core Components of Apache Kafka
- Kafka Use Cases
- Deep Dive into Kafka Architecture
- Kafka in Action: Real-World Applications
- Key Features and Strengths of Apache Kafka
- Best Practices for Implementing Kafka
- Challenges and Considerations in Kafka Deployment
- The Future of Apache Kafka
- Conclusion
In the world of real-time data processing and streaming analytics, Apache Kafka has emerged as a leading platform. It’s a distributed event streaming platform capable of handling more than trillions of events a day. It was initially conceived as a messaging queue, and Kafka has evolved into a full-fledged event streaming platform.
This article provides a comprehensive overview of Apache Kafka, exploring its architecture, core concepts, and extensive applications.
We’ll also delve into Kafka use cases, illustrating how various industries leverage their power to drive real-time data insights and decision-making.
What is Apache Kafka?
It is a project nurtured by the Apache Software Foundation and is a stream-processing system crafted using Scala and Java. Its primary aim is to offer a consolidated platform characterized by high throughput and minimal latency, ideal for managing real-time data streams.
At its core, it functions as a scalable publish/subscribe messaging queue, designed as a distributed transaction log. This feature renders it an indispensable tool for enterprise architectures that need to efficiently handle streaming data.
Core Components of Apache Kafka
- Producer: Responsible for publishing records to Kafka topics.
- Consumer: Reads and processes records from topics.
- Broker: A server in a Kafka cluster that stores data and serves clients.
- Topic: A category or feed name to which records are published.
- Partition: Kafka topics are split into partitions for scalability and parallelism.
- ZooKeeper: Manages and coordinates Kafka brokers.
Kafka Use Cases
Kafka’s design and capabilities make it suitable for various scenarios, including:
- Real-Time Analytics: Powering applications that require analysis of data in motion.
- Event Sourcing: Capturing changes to an application state as a sequence of events.
- Log Aggregation: Collecting and processing logs from multiple services.
- Stream Processing: Enabling complex transformations and processing of stream data.
- Integration: Simplifying the integration of different applications and data systems.
Deep Dive into Kafka Architecture
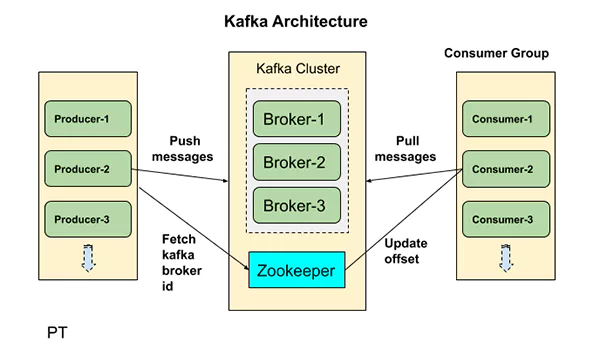
The Publish-Subscribe Model
At its core, Kafka implements a publish-subscribe messaging model. Producers publish messages to topics, and consumers subscribe to topics to read the messages. This model separates the producers from the consumers, allowing them to operate at different speeds and scales.
Distributed System Design
Kafka’s architecture is inherently distributed. It runs as a cluster of brokers, with partitions distributed and repeated across multiple nodes. This design ensures fault tolerance, high availability, and scalability. Data is written to disk and replicated within the cluster to prevent data loss.
Durability and Reliability
It ensures data durability through its commit log design. Data is written to persistent logs, which provides fault tolerance and allows for the replay of data. The replication factor can be configured to increase data reliability and availability.
Kafka in Action: Real-World Applications
Financial Services
In the financial sector, Kafka is used for real-time fraud detection systems, customer 360 views, and operational metrics. It enables banks and financial institutions to process millions of transactions in real-time, providing up-to-date information for decision-making and reporting.
Retail and E-Commerce
Retailers use Kafka for real-time inventory management, order processing, and customer personalization. It helps in tracking user activity on websites, managing supply chains, and providing personalized recommendations to customers.
Telecommunications
Telecom companies leverage it for network monitoring, real-time billing systems, and customer data management. It allows them to handle large volumes of call data records and network traffic data efficiently.
Internet of Things (IoT)
In IoT applications, Kafka is used to collect and process data from millions of devices. It supports scenarios such as real-time analytics, monitoring, and predictive maintenance.
Healthcare
Kafka finds applications in healthcare for patient monitoring systems, real-time diagnostics, and interoperability between different systems. It allows a quick and reliable data exchange between various healthcare providers and devices.
Key Features and Strengths of Apache Kafka
High Throughput
Kafka’s design allows it to handle hundreds of thousands of messages per second, making it suitable for scenarios that require high-volume data processing.
Scalability
Kafka clusters can be scaled out without downtime. New brokers can be added, and topics can be partitioned and replicated across multiple nodes to handle more load.
Durability
Kafka’s persistent storage mechanism ensures that data is not lost even in the case of node failures. The replication factor can be configured to control the durability level.
Low Latency
Kafka is optimized for low-latency message delivery, making it ideal for real-time applications that require quick data processing and delivery.
Fault Tolerance
Kafka’s distributed nature and replication model provide fault tolerance. If a broker fails, other brokers can serve the data, ensuring continuous operation.
Best Practices for Implementing Kafka
Capacity Planning
Understand the volume of data and the processing requirements to size the Kafka cluster appropriately. Consider factors like message size, throughput, and retention policies.
Monitoring and Management
Implement robust monitoring to track the health and performance of the Kafka cluster. Use tools and services that provide insights into throughput, latency, and system health.
Security Considerations
Secure the Kafka cluster by implementing authentication, authorization, and encryption. Use ACLs to control access to topics and ensure data is encrypted in transit and at rest.
Data Retention Policies
Configure data retention policies based on the use case requirements. Consider how long data needs to be stored and the implications for storage capacity and performance.
Consumer and Producer Configuration
Modify the configuration of producers and consumers for reliability and performance. Understand the trade-offs between latency, throughput, and durability.
Challenges and Considerations in Kafka Deployment
Complex Configuration and Tuning
Kafka’s wide array of configuration options can be daunting. Proper tuning is necessary for optimal performance, but it requires a deep understanding of the system.
Data Consistency and Ordering
Ensuring data consistency and correct ordering can be challenging, especially in distributed environments. Understand the delivery semantics and configure the system accordingly.
Cluster Management and Scaling
Managing and scaling a Kafka cluster requires careful planning and operational expertise. Consider using managed services or specialized tools to simplify these tasks.
Integration with Existing Systems
Integrating Kafka with existing data systems and applications can be complex. Ensure compatibility and plan for data format conversions and system interactions.
The Future of Apache Kafka
Continued Evolution and Innovation
The Kafka community is vibrant and continuously evolving. Expect ongoing improvements in performance, ease of use, and features that extend its capabilities.
Expansion into New Domains
As more industries recognize the value of real-time data processing, Kafka’s adoption is set to grow. It will continue to expand into new domains and use cases.
Integration with Advanced Technologies
Kafka will integrate more and more with advanced technologies like AI, machine learning, and edge computing. These integrations will enhance its capabilities and open up new possibilities for real-time data processing.
Conclusion
Apache Kafka has established itself as an important component in the data infrastructure of organizations that prioritize real-time data processing and analytics. Its strong architecture, high performance, and scalability make it suitable for a wide range of use cases across various industries.
By understanding its core concepts, architecture, and best practices, organizations can unlock the full potential of Kafka to drive real-time insights and decision-making.
As Kafka continues to evolve, it will undoubtedly remain at the forefront of the event streaming landscape, empowering businesses to harness the power of their data in real-time.
Also Read: The Programmer’s Guide to Integrated Software Development