Top 5 Stages of High-Volume Real Estate Data Aggregation

Real estate is heavily dependent on the data, but collecting data is only half the job. The real actions come into the practice when the information comes from various sources, not one but dozens. Each one is set on their own different format and has quality issues.
This is where real estate data aggregation helps. It serves as a structured approach for businesses to turn scattered property information into reliable business information.
Keep reading this article to explore the top 5 stages of high-volume real estate data aggregation.
Key Takeaways
In a strong real estate data aggregation, missing even a small percentage of required data can affect the research.
Fake records, outdated entries and inaccurate addresses can negatively affect the investment and valuation decisions.
Long-term growth depends more on efficient serving methods that keep the present data more actionable.
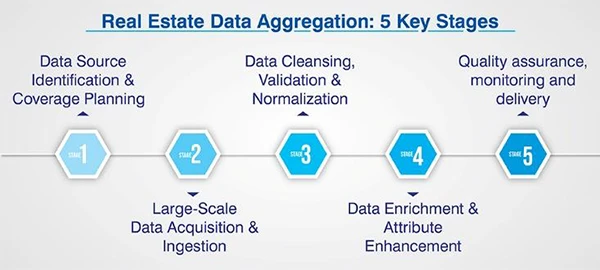
5 Stages of Real Estate Data Aggregation
Real estate data aggregation is not a single task. It is a unified, multi-step real estate data workflow. From the data collection process to the real estate ETL process, successful aggregation depends on systematic ingestion, data normalization, deduplication, and data testing to deliver robust, high-volume property intelligence.
Stage 1: Data Source Identification & Coverage Planning
This is the initial phase in which an accurate method of real estate data aggregation will be formed through defining the data to collect and the manner in which it should be collected.
The identification of structured and unorganized real estate data sources as well as setting up a plan for geographic coverage are also part of this process.
Avoiding gaps in geographic coverage can notably affect the valuation of a property, the analogs used in the sale or valuation of a property, and the resulting analytics from real estate data.
Developing a detailed source strategy will result in efficient MLS data aggregation and dependable regional market trends.
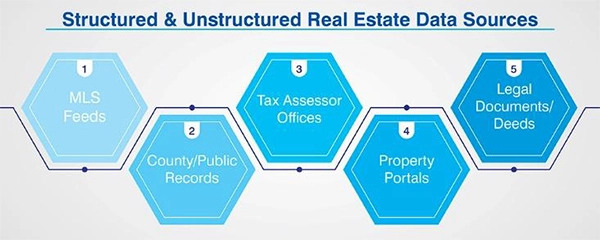
Structured and unstructured real estate data sources include:
- MLS Feeds – Structured listing data including Active, Pending and Sold Properties
- County/Municipal Public Records – Ownership History, Transfers, Encumbrance
- Tax Assessor Office – Actual Values, Parcel Information, Exemption Status
- Property Portal Platforms – Consumer-facing platforms with supplemental listing data
- Legal Document/Scanned Deed – Unstructured data sources which ask for Optical Character Recognition (OCR) and Parsing
Why does this matter?
- Missing 5-10% of valid sources may skew property valuations.
- Insufficient geographic coverage may weaken the parallel analysis and market analytics of your data.
Stage 2: Large-Scale Data Acquisition & Ingestion
Once you’ve learned about the most common data sources for your real estate business, you’ll need to obtain this data and get it into your system – but it will be HUGE.
You can collect and funnel property data from real estate sources to a central location using a strong property data ingestion model.
A good real estate data scraper/ingester should allow for steady, high volume, low-latency data flow with minimal gaps across markets.
There are four main ways to get property data, and they all have different levels of technical difficulty.
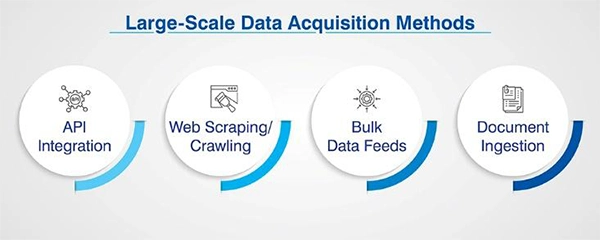
These four main acquisition methods are:
- API Integration: Includes Direct Feeds from MLS Systems, Assessor Portals & Third Party Data Partners
- Web Scraping/Crawling: Includes automated property data collection from Multiple Sources at Scale (i.e., portals, listings sites)
- Mass Data Feed: Includes Transfer of Large Files (CSV, JSON, XML) from County Offices and Data Vendors.
- Document Ingestion: This includes mining PDFs, TIFFs and scanned deeds using Optical Character Recognition (OCR) and AI-Powered Parsing Pipelines.
But the friction that goes with real estate data scraping and ingestion at scale is severe.
The typical issues encountered by engineering teams are:
- Rate Limits: These will block API Calls or slow down bulk ingestion.
- Changing Schemas: Since County Portals and MLS Systems are routinely changing their data structures without warning, this creates additional schema costs for engineers. Anti-Scraping Mechanisms: This refers to CAPTCHA’s, IP Blocks, Session Timeouts etc.
- Inconsistent Update Cycles: For example, one county may refresh data every week while another may only update data quarterly.
Overcoming the above listed problems ensures robust property data ingestion and uninterrupted downstream processing. Companies can realize cost savings and noticeably faster turnaround times, thus creating a compelling argument for the use of custom property data ingestion infrastructure rather than ad-hoc solutions.
Stage 3: Data Cleansing, Validation & Normalization
Property data acquired by an organization is often not accurate or solid enough to rely upon.
According to Gartner, poor data quality costs organizations an average of $12.9 million annually. In real estate, where valuation, investment, and comparable metrics hinge upon the accuracy of records, the risks associated with inaccurate property data are even greater.
A clean process of data validation divides a valid analytics pipeline from a pipeline that quietly gives false information at scale.
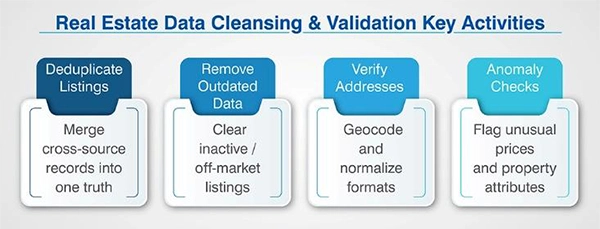
Validation of property data is accomplished via multiple key activities:
- Duplicate Listing Detection & Merging – Properties can show up on multiple MLS feeds, Multiple Listing Service websites, county database sources, etc., as separate listings that contain opposing data related to the property.
Thus, an intelligent process to resolve replica listings & establish a single source of truth is required.
- Removal of Outdated / Off-Market Listings – Listings which are no longer current can strongly affect analysis of the current state of active markets & affect price modeling; therefore, it is important to cut out the outdated listings in a timely fashion.
- Address Verification / Correction – Geocoding & Normalization of Locations is needed because if the formatting of addresses in county records is not linear, it could lead to silent errors in future data processing.
- Price / Attribute Anomaly Checks – Automated rulesets look for values (bedroom count, square footage, etc.) & prices that fall outside what would be termed reasonable for a particular geographic area.
The final goal of a successful Data cleansing, validation & normalization step is to have a genuine, current & ready-for-analytics dataset of properties where trustful decisions can be made.
Stage 4: Data Enrichment & Attribute Enhancement
Data cleaning is simply the start. It’s the enriched data that gives you an edge. Listings with rich property keywords have properties sold 23 percent quicker than simple listings. And as a result, platforms that utilize enriched, multi-dimensional data are likely better than those using basic property records alone.
Real estate data enrichment is where you turn a simple property record into a decision ready tool for the end user.
Some examples of enrichment layers that can be applied at this stage are:
- Property Info – beds, bathrooms, square footage, building material, etc. are appended to the property record and verified so that a true comparable exists.
- Ownership & Transaction History – ownership contact information, mortgage history, open liens, pre-foreclosure status, etc. are posted to the property record giving a complete financial picture of each property.
- Market Indicators – price trend, days on market (DOM) and other neighborhood ask signals are layered on top of the property record to give smarter models for investments.
- Rental Yields & Valuation Signals – the results from AVMs and rental values are fed into the property record for use in underwriting, portfolio analysis and investor targeting.
As such, the downstream impact of enrichment is very real. The reliability of any AVM is directly shaped by the quality of its input data. There is no such thing as “garbage in, garbage out” when it comes to data.
Therefore the effectiveness of your valuation models will directly relate to the level of enrichment done.
Enriched records enhance analytical capacity but also create direct engagement and conversion chances.
Stage 5: Quality Assurance, Monitoring and Delivery
The data enrichment process does not wrap up with data aggregation. It concludes at the point where the data has been reliably and regularly delivered. A data set of such size implies a much greater effort than a one-time build.
Real estate data management at the enterprise level is an ongoing operational task rather than a project with a “finish” line.
- Standardized schema: Consistent field names, data types and taxonomies which enable effortless integration to downstream applications and analytical platforms
- Data warehouses/lakes: Central repositories which can contain sorted records as well as unstructured (raw) data for historical analysis and machine learning (ML) model development
- API-ready datasets: Low latency endpoints allow real time property intelligence to be passed from ATTOM to PropTech applications, CRMs and underwriting systems
- Search optimized property records – Records which are structured for fast retrieval, geospatial queries and loading in front-end listings
Common Bottlenecks in High-Volume Real Estate Data Aggregation
High volume aggregation of real estate information poses an operational challenge that can limit how quickly and safely data is delivered, as well as the overall scalability of the system.

Best Practices for Scaling Real Estate Data Aggregation Successfully
Successfully scaling your real estate data aggregation operation is based on setting up a balance among automation, data quality and the freedom to adapt to changing future needs.
The more sources you have and the wider the volumes of data, the less likely the systems used to supply data will stay scalable without losing speed or accuracy of data delivery.

Conclusion
A major confusion one gets is that more data will lead to better outcomes. But in reality, the one that get the most benefit from the real estate data is not the one that gain most data. They are the ones who actually know how to structure and use it for the scale operations.
What makes this process better is the aggregation process. It helps to convert the scattered property records into a trustworthy source that serves investment guide and faster decisions.
In the end, the will to manage that information better is holding the same importance as the data itself.
FAQs
- Why is real estate data aggregation confusing?
Property data comes from various sources — portals and public records. This makes it tough to sort and use for decision-making. - What is the major challenge in large scale property data collection?
Ensuring consistency is much tougher than collecting the data from various sources. Many entries are fake, outdated and more, increasing confusion. - How early should real estate data be updated?
The right number depends on the source, but for better accuracy, continuous monitoring and refresh should be performed.